1. 문제
2. 풀이
백트래킹, 메모이제이션, DP을 모두 적용시킬 수 있는 아주 흥미로운 문제이다.
(아물론 제약조건 때문에 DP를 적용한 코드만 통과했다.)
3가지 풀이방법 모두 완전탐색을 기반으로 한다.
다만 그 효율성을 어떻게 높였는지에 따라 알고리즘이 분류된 것일 뿐이다.
- 백드래킹은 가지치기 코드를 통해 유효하지 않은 상태트리(경우의 수)를 더이상 탐색하지 않는다.
- 메모이제이션은 탑다운 방식으로 탐색을 이어나가는 중, 중복되는 상태트리를 만나는 경우 저장된 값을 불러온다.
- DP는 바텀업 방식으로 탐색을 하되, 이전 탐색의 값을 기억해두었다가 적절하게 재활용하여 완전탐색을 만족시킨다.
개인적으로 백트래킹과 메모이제이션은 어느 정도 코드의 정형화가 가능하기에 상대적으로 쉬운 반면,
DP는 말그대로 "적절하게 재활용" 하는 법을 생각해내야하기에 내게는 아직 멀게만 느껴진다.
아무튼 운좋게도 이번 문제는 "적절하게 재활용" 하는 법을 생각해냈다.
2.1. 백트래킹 풀이
==시간초과==
가장 먼저 자연스럽게 떠오르는 풀이이다.
하지만 시간초과가 발생한다.
[백트래킹]
- 후보군 출력: (0, 0)부터 주어진 조건대로 오른쪽과 아래쪽으로 점프하면서 후보군을 출력한다.
- 가지치기: 범위를 벗어나면 더 이상 탐색하지 않는다.
- 가지치기라고 하기엔 종료조건에 가깝지만...
- 종료조건: (N-1, N-1)에 도착했을 경우, 경로를 1 증가시킨다.
import sys
input = sys.stdin.readline
def backtracking(i, j):
global path
# 가지치기
if i >= N or j >= N: # 범위를 벗어나는 경우
return
# 종료조건
if i == N - 1 and j == N - 1:
path += 1 # 경로 증가
return
# 후보군 출력
jump = arr[i][j] # 현재 지점에서 점프하는 거리
backtracking(i + jump, j) # 아래쪽으로 점프
backtracking(i, j + jump) # 오른쪽으로 점프
N = int(input())
arr = \[list(map(int, input().split())) for \_ in range(N)\]
path = 0
backtracking(0, 0)
print(path)2.2. 메모이제이션 풀이
==RecursionError==
==메모리 초과==
한 번 메모이제이션을 사용해서 풀어보고 싶었다.
결과값이 나오지 않은데다가, 내가 메모이제이션이 익숙치 않아서 이 코드가 맞는지 틀렸는지는 확실하지 않다.
일단 테스트 케이스와 질문검색에 있는 반례들은 모두 통과했다.
Recursion Error가 발생하여 sys.setrecursionlimit(10**7)로 재귀호출의 최댓값을 늘려주었지만, 그러자 이번에는 메모리 초과가 발생했다.
아마도 탑다운 방식에서 상태트리가 겹치는 경우가 적기 때문인 것 같다.
[메모이제이션]
memo[i][j]는 arr[i][j]에서 목적지까지 가는 경로의 수를 저장하고 있다.
- 베이스 반환문: 범위를 벗어나면 0을 반환한다 (목적지까지 경로가 없음)
- 메모이제이션 값이 있을 경우
- 해당 값 반환
- 기본적으로 목적지에서는 1을 반환한다: memo[N-1][N-1] = 1
- 메모이제이션 값이 없을 경우
- 현재위치에서부터 경로 수 = 아래쪽으로 점프한 위치에서의 경로 수 + 오른쪽으로 점프한 위치에서의 경로 수
import sys
sys.setrecursionlimit(10**7)
input = sys.stdin.readline
def memoization(i, j):
if i > N - 1 or j > N - 1: # 베이스 반환문
return 0
if memo[i][j]: # 메모이제이션 값이 있으면 해당 값을 반환
return memo[i][j]
jump = arr[i][j] # 메모이제이션 값이 없을 경우
memo[i][j] = memoization(i + jump, j) + memoization(i, j + jump) # 현재 위치 메모이제이션 값 = 오른쪽 점프한 곳에서 메모이제이션 값 + 왼쪽 점프한 곳에서 메모이제이션 값
return memo[i][j]
N = int(input())
arr = [list(map(int, input().split())) for _ in range(N)]
memo = [[0] * N for _ in range(N)]
memo[-1][-1] = 1 # 목적지에서는 1을 반환 (베이스 반환 조건)
print(memoization(0, 0))2.3. DP 풀이

마지막 DP. 생각보다 시간도 훨씬 적게 걸렸다.
[DP]
일단 가장 중요한 DP배열이 저장하는 값은 다음과 같다
DP[i][j]: 시작지점부터 (i, j)까지의 경로 수
그러면 DP 배열을 업데이트 하는 방법은 간단한다.
DP[i][j]에서 다음 번으로 점프할 위치에, DP[i][j]의 값을 더해주면 된다.
* jump = arr[i][j]
* DP[i+jump][j] += DP[i][j]
* DP[i][j+jump] += DP[i][j]
Ex. 다음과 같이 arr와 DP의 일부의 값이 있다면, 아래 그림처럼 코드가 진행된다

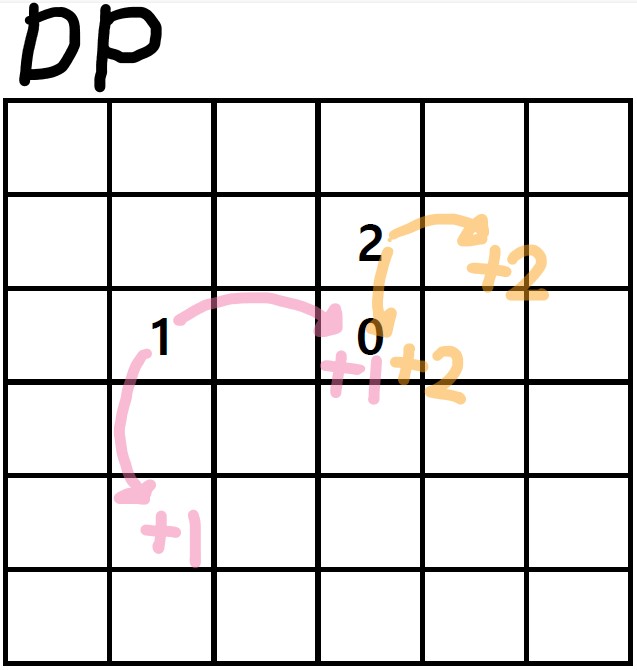
단, DP배열은 시작지점부터 목적지점까지 거리순으로 이뤄저야 한다
이게 무슨 말인가 하면 다음과 같이 대각탐색을 하면서 DP를 업데이트 해야한다는 말이다.(우상향하는 탐색도 상관없다)
왜냐하면 점프 자체를 오른쪽 & 아래쪽으로 하기 때문에, 그림처럼 대각탐색을 해야 순서에 맞게 DP가 업데이트 된다.
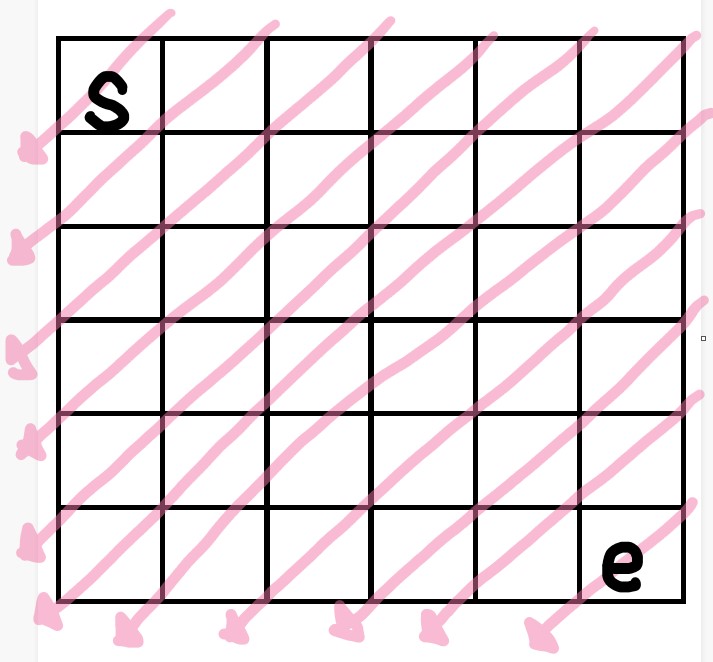
import sys
input = sys.stdin.readline
N = int(input())
arr = [list(map(int, input().split())) for _ in range(N)]
dp= [[0] * N for _ in range(N)]
dp[0][0] = 1
for n in range(2 * N - 2): # 좌하향하는 대각선 탐색 코드: 여기부터 ~
if n < N: # 그냥 내 생각대로 맘대로 짰다
i = 0
j = n
else:
i = n - N + 1
j = N - 1
for m in range(N - abs(n + 1 - N)):
ci, cj = i + m, j - m # ~ 여기까지
jump = arr[ci][cj] # 현재위치 (ci, cj)에서의 점프 값
path = dp[ci][cj] # 현재위치 DP값(시작지점부터 현재위치까지의 경로 수) 읽어오기
if ci + jump < N:
dp[ci + jump][cj] += path # 아래쪽 점프위치 DP 업데이트
if cj + jump < N:
dp[ci][cj + jump] += path # 오른쪽 점프위치 DP 업데이트
print(dp[-1][-1])'Code Review > BaekJoon' 카테고리의 다른 글
| [ 백준 1922번 네트워크 연결 ] Python 코드 (MST) (0) | 2022.10.26 |
|---|---|
| [ 백준 21610번 마법사 상어와 비바라기 ] Python 코드 (Simulation) (0) | 2022.10.24 |
| [ 백준 2156번 포도주 시식 ] Python 코드 (DP) (0) | 2022.10.24 |
| [ 백준 9465번 스티커 ] Python 코드 (DP) (0) | 2022.10.24 |
| [ 백준 12865번 평범한 배낭 ] Python 코드 (DP) (1) | 2022.10.19 |



